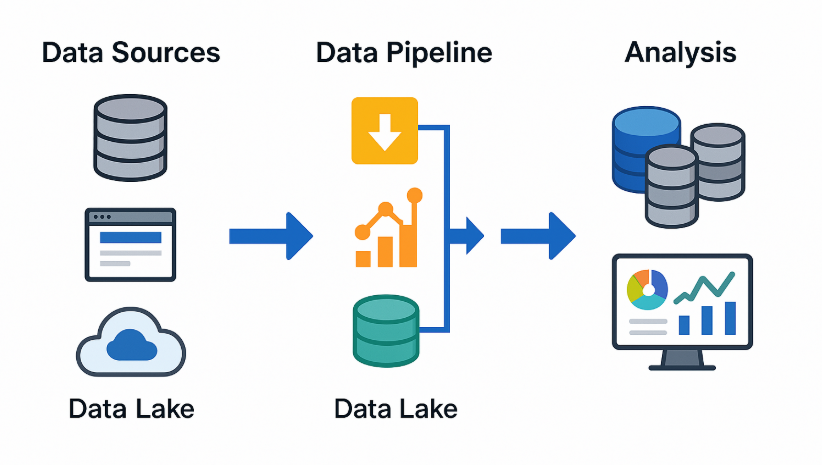
Data Pipeline คืออะไร? ทำไมระบบวิเคราะห์ข้อมูลต้องมีมากกว่าฐานข้อมูลเดียว
ธุรกิจยุคใหม่ไม่เพียงพอแค่ “มีข้อมูล” แต่ต้องมี “ระบบจัดการข้อมูล”
การออกแบบ Data Pipeline ช่วยให้ข้อมูลของคุณ พร้อมใช้ พร้อมวิเคราะห์ และพร้อมตัดสินใจ ได้เสมอ
Data Pipeline คืออะไร?
Data Pipeline คือเส้นทางการเดินทางของ “ข้อมูล” ตั้งแต่จุดที่ข้อมูลเกิด → ถูกดึงเข้าสู่ระบบ → ถูกแปลง (จัดระเบียบ/ทำความสะอาด) → จัดเก็บอย่างเหมาะสม → วิเคราะห์ → ใช้ในการตัดสินใจทางธุรกิจ
เปรียบเหมือน “ท่อน้ำ” ที่ส่งข้อมูลจากหลายที่ ไปยังปลายทางที่พร้อมดื่มได้
องค์ประกอบสำคัญของ Data Pipeline
- Source (ต้นทาง)
เช่น: Database, IoT, Web API, CRM, Excel, Google Analytics - Ingestion (การนำเข้า)
ดึงข้อมูลเข้า เช่น ด้วย Python, Airbyte, Fivetran, Kafka - Transformation (การแปลงข้อมูล)
แปลงให้อยู่ในรูปที่พร้อมใช้ เช่น dbt, Pandas, Spark - Storage (จัดเก็บ)
ใช้ Data Lake หรือ Data Warehouse เพื่อเก็บระยะยาว เช่น S3, BigQuery - Analysis & Visualization (วิเคราะห์/แสดงผล)
เช่น Power BI, Looker Studio, Superset, Metabase
ทำไมแค่ “ฐานข้อมูลเดียว” ไม่พออีกต่อไป?
| ปัญหา | หากไม่มี Data Pipeline |
|---|---|
| ข้อมูลกระจัดกระจาย | ต้องเปิดดูทีละระบบ, เชื่อมต่อยุ่งยาก |
| การวิเคราะห์ไม่ทันเวลา | ข้อมูลไม่สด → ตัดสินใจช้า |
| มีข้อมูลซ้ำ / ผิด | ไม่มีการทำความสะอาดข้อมูล |
| ขาดมุมมองรวม | วิเคราะห์เฉพาะแหล่งเดียว ไม่เห็นภาพรวมธุรกิจ |
ธุรกิจยุคใหม่ต้องรวมข้อมูลจากหลายที่ให้เป็น “ชุดเดียวกัน” เพื่อวิเคราะห์อย่างแม่นยำ
เครื่องมือยอดนิยมที่ใช้สร้าง Data Pipeline
| ประเภท | ตัวอย่าง |
|---|---|
| Ingestion | Apache Kafka, Airbyte, Fivetran, Cloud Function |
| Transformation (ETL) | dbt, Pandas, PySpark, Dataform |
| Orchestration | Apache Airflow, Prefect, Dagster |
| Storage | BigQuery, Snowflake, Redshift, Data Lake (S3/GCS) |
| Visualization | Power BI, Looker Studio, Superset, Metabase |
ความแตกต่าง: Data Lake vs Data Warehouse
| ด้านเปรียบเทียบ | Data Lake | Data Warehouse |
|---|---|---|
| ประเภทข้อมูล | ได้ทั้งข้อมูลดิบ (Raw) | ข้อมูลโครงสร้างชัดเจน (Structured) |
| รูปแบบไฟล์ | CSV, JSON, Log, รูปภาพ, เสียง ฯลฯ | ตาราง/ฟิลด์ แบบ SQL |
| ความยืดหยุ่น | สูง | ต่ำกว่า (เน้นความเร็ว) |
| ตัวอย่าง | AWS S3, Google Cloud Storage | BigQuery, Snowflake |
✨ Data Lake = เก็บทุกอย่าง
📊 Data Warehouse = วิเคราะห์เร็ว, ทำ Dashboard ได้ทันที
ตัวอย่างใช้งานจริงในธุรกิจ
ธุรกิจ eCommerce
- แหล่งข้อมูล: Shopify + Facebook Ads + Google Analytics
- ใช้ dbt แปลงข้อมูล, เก็บที่ BigQuery
- วิเคราะห์พฤติกรรมลูกค้า, ROI, LTV บน Looker Studio
Smart Farm
- รับข้อมูล IoT จาก Sensor
- ประมวลผลด้วย Airflow + Python
- วิเคราะห์อุณหภูมิ/ความชื้นแบบเรียลไทม์ใน Dashboard
โรงพยาบาล
- รวมข้อมูลจาก Lab, Doctor Note, ระบบนัดหมาย
- แสดงแนวโน้มผู้ป่วย, ระยะเวลารอพบแพทย์, วิเคราะห์คุณภาพบริการ